
This article reviews recent advances in machine learning that have provided competitive alternatives to graphics processing. To keep model operation timely, both business and research necessitate GPU access. Unfortunately, this hardware currently costs 10x the price per GB of memory compared to system RAM.
To cut our GPU dependency we can employ the following techniques:
Training
- Fine-tuning pre-trained models
- Reducing computational complexity
- CPU offloading
Inference
- Optimising models for their deployment targets
- Reducing models
This post describes how these techniques improve performance and reviews their effectiveness. Cutting GPU allows more avenues for model deployment and democratizes model operation, so it’s promising that these techniques will continue to evolve.
GPUs: how and why?
Competition in ML research drove accuracy upwards by increasing the number of model parameters into the billions, and employing such magnitudes on quick timescales requires stream processing architectures like GPUs. Without this speedup, research labs can’t tune and repeat their experiments, and businesses are slower to meet consumer demand.
GPUs excel because they are designed for vector computations, which are very common in modern machine learning. Indeed, these computations can perform up to 200x quicker on a GPU [1]. We can understand the computations composing a machine learning model by considering training as a directed cyclic graph:

Here, golden circular nodes represent states which occupy GPU memory: batch, layer activations, gradients and model parameters. Grey rectangles represent vector computations from the connected states, and the result is stored in the state at the end of the outgoing edge. Going once clockwise around the graph represents one training loop, which repeats until convergence. Now let’s compare training with inference:
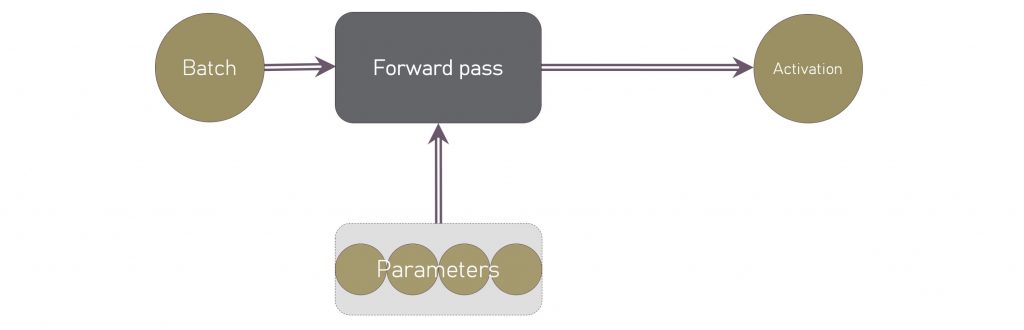
Observe that much less GPU is required for inference: we hold just the batch and parameters in memory, and compute only the final layer activation with the forward pass.
Cut GPU from model training
I: Fine-tuning pre-trained models
Fine-tuning expedites our model training through better initialization, and gives the option to constrict additional training computations to just the final layers by using the inference of a pre-trained model as features. Re-using our pre-trained parameters this way is very cost-effective: we can train a large model on a huge domain-invariant dataset once and use it multiple times over for high generalization.
In many domains, research authors have open-sourced large generalized models and successfully fine-tuned them on varying downstream tasks. Some examples include:
- BERT, a language model trained on Wikipedia and book corpora which reached state-of-the-art on 11 NLP tasks [2]
- VGG16, an image classifier achieving 92.7% top-5 test accuracy on ImageNet [3]
This technique is extremely common due to its effectiveness, and libraries like transformers have made integration and fine-tuning simple by providing a universal interface [4].
II: Reducing computational complexity
We can optimize bottleneck processes to run with reduced space and time complexity. In doing this, we increase GPU memory and time efficiency during operation.
One such process is self-attention, the mechanism of a transformer model, which has a space complexity of O(L2) where L is the input sequence length. Over the past two years, a number of papers questioned whether this quadratic complexity is essential, offering solutions including:
- Locality sensitive hashing attention (e.g. ReFormer, SLIDE) [5, 6]
- Global attention and sliding window attention (e.g. LongFormer, BigBird) [7, 8]
- Linear attention (e.g. LinFormer) [9]
- Fast attention via positive orthogonal random features (e.g. Performer) [10]
III: CPU offloading
Moving computations to CPU reduces the GPU memory overhead by storing states in system RAM. We sacrifice a bit of speed to achieve this, but low-complexity computations can be offloaded to CPU without significant slowdown.
ZeRO-Offload executes this offload after the backward pass, moving gradients into RAM and performing parameter updates on CPU [11]. This strategy minimizes communication between CPU and GPU, reserving 10x more GPU memory.
Cut GPU from model inference
I: Optimising models for their deployment targets
Once the model is trained, we accelerate the inference graph for the hardware on which we plan to deploy. We make the model smaller, faster, and highly optimized for environments that even don’t have any GPU access.
ONNX and ONNX Runtime are open source libraries to convert and run models at up to 17x their original speeds [12]. ONNX converts the forward pass into a smaller, interoperable format that is ready for deployment practically anywhere. The runtime then provides accelerators that take advantage of the specific compute capabilities of the target hardware.
II: Reducing models
We can shrink our trained model’s memory footprint by decreasing parameter precision, distilling it or even removing sets of parameters entirely (“pruning”). These techniques sacrifice accuracy to reduce the size of the model while retaining its decision boundaries.
The benefits of reducing also carry over to inference speed. In the case of decreasing parameter precision, swapping to 8-bit integer parameters decreases model size by 75% and grants us a 4x speed boost because of faster integer arithmetic [13].
Review & speculation
Because inference requires no backward passes or parameter updates, the above techniques work extremely well to make pure CPU predictions viable. ONNX and ONNX Runtime have been very welcome additions to the machine learning engineering toolkit, and in some cases make inference even faster than GPU. The consequences are substantial: even model deployment to less powerful devices like mobile phones are possible.
Note that large tech companies like Microsoft, Google and IBM support much of the research that published the techniques discussed. It’s possible they have a vested interest in reducing market demand for graphics processors, which they currently don’t manufacture themselves.
In total, the trend of reducing GPU dependency does great things for research democracy, since it facilitates smaller laboratories reproducing state-of-the-art results from big-budget experiments.
Because of these reasons, we will continue to see more evolution in GPU cutting.
Conclusion
GPU usage provides huge speed benefits to machine learning practitioners, with large costs that can be mitigated. The benefit of GPU architecture in model operation is making the following vector computations quicker:
- Forward pass
- Backward pass
- Parameter update
The amount of GPU needed for training can be cut by fine-tuning, reducing computational complexity and offloading to CPU, but sacrifices in speed and accuracy must undergo consideration. Since inference only contains forward pass, optimizing and reducing models make prediction fast enough to cut GPUs entirely from production scenarios.
The advancements enabling this change brought dramatic cost reductions for both research and business, and opened new avenues for model deployment. This makes me very excited to see what comes next.
References
[2] BERT on Github, with links to original paper
[4] 🤗 transformers on Github, providing access to a vast library of state-of-the-art language models
[5] ReFormer: The efficient Transformer
[7] LongFormer: The long document Transformer
[8] BigBird: Transformers for longer sequences
[9] Linformer: Self-attention with linear complexity
[10] Rethinking attention with Performers
[11] ZeRO-Offload: Democratizing billion-scale model training